MapReduce
MapReduce
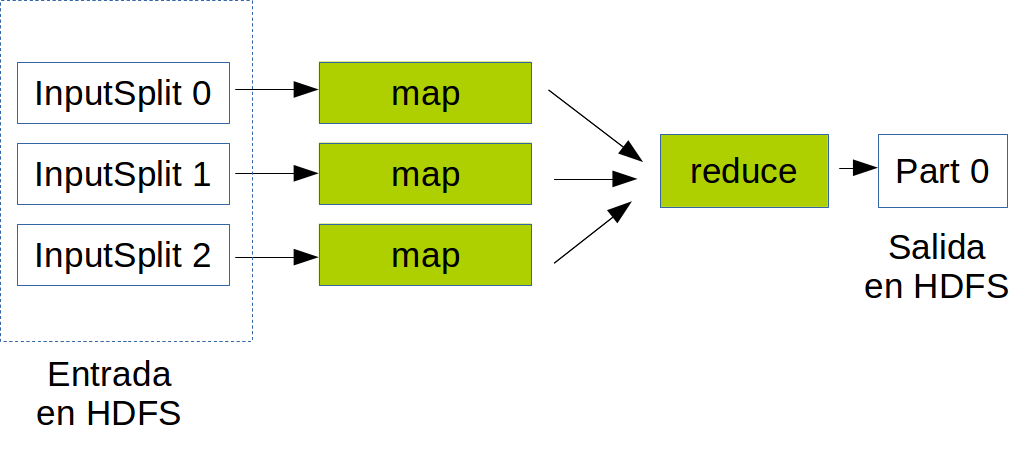
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
MapReduce
Launching a job
To launch a job:
yarn jar job.jar DriverClass input outputList MR jobs
To list running MR jobs:
mapred job -listCancelling a job
To cancel a job:
mapred job -kill [jobid]Monitoring
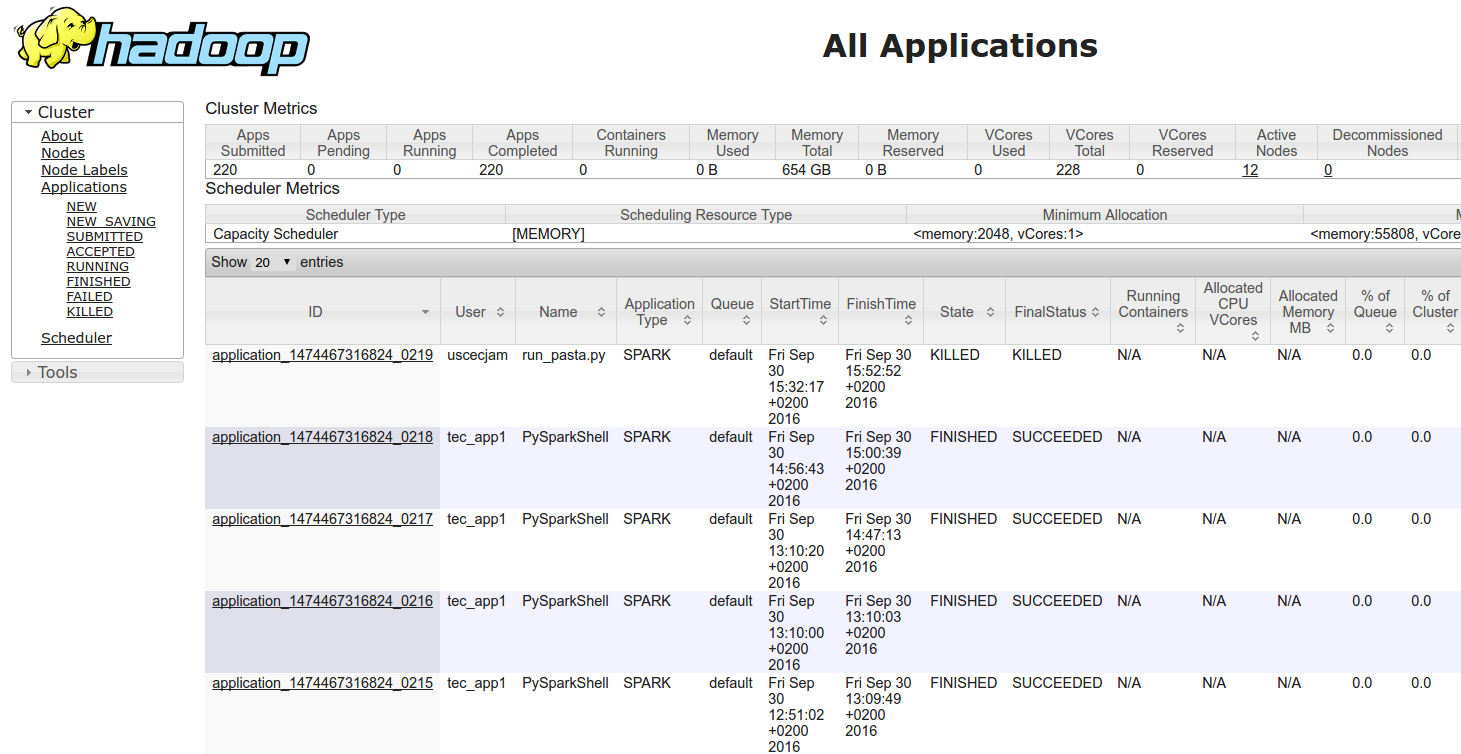
You can easily monitor your jobs using the YARN UI from the WebUI:
Job History
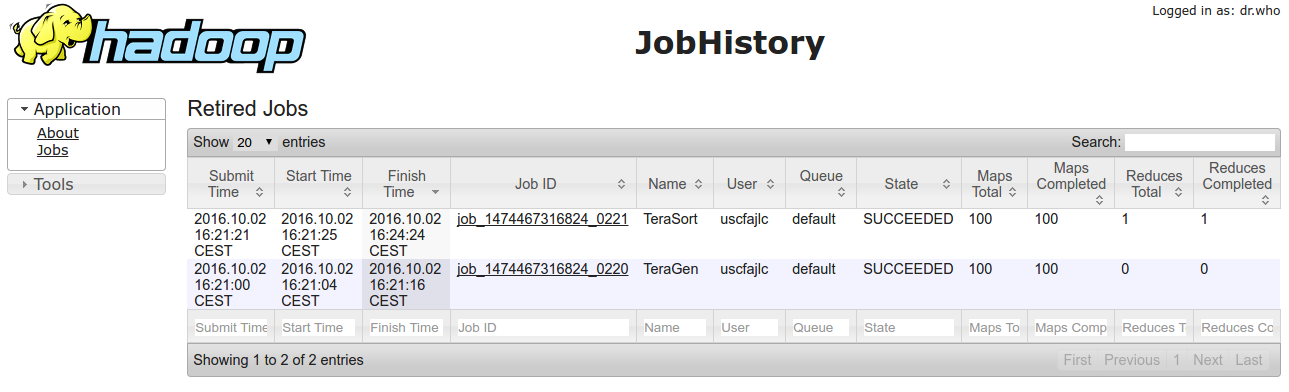
You can see finished jobs using the MR2 UI from the WebUI:
MapReduce for Java developers
Development Environment Setup
- For a sample Maven-based project use:
git clone https://github.com/bigdatacesga/mr-wordcount - Import the project in Eclipse using m2e or in Intellij
- If using an IDE like Eclipse or Intellij it can be useful to:
# Download sources and javadoc mvn dependency:sources mvn dependency:resolve -Dclassifier=javadoc # Update the existing Eclipse project mvn eclipse:eclipse # Or if you using Intellij IDEA mvn idea:idea
Maven Basic Usage
Compile:
mvn compileRun the tests
mvn testPackage your app
mvn packageManual Process
If you prefer to compile and package manually:
javac -classpath $(hadoop classpath) *.java
jar cvf wordcount.jar *.class
MapReduce Program
Basic components of a program:
- Driver: management code for the job or sequence of jobs
- map function of the Mapper
- reduce function of the Reducer
Driver Code
public class Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Driver.class);
job.setJobName("Word Count");
job.setMapperClass(WordMapper.class);
job.setCombinerClass(SumReducer.class);
job.setReducerClass(SumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
System.exit(success ? 0 : 1);
}
}
Map Code
public class WordMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
for (String field : line.split("\\W+")) {
if (field.length() > 0) {
word.set(field);
context.write(word, one);
}
}
}
}
Reduce Code
public class SumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(
Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int wordCount = 0;
for (IntWritable value : values) {
wordCount += value.get();
}
context.write(key, new IntWritable(wordCount));
}
}
MapReduce Streaming API
Quick how-to
- We write two separated scripts: Mapper y Reducer
- The Mapper script will receive as stdin the file line by line
- The stdout of the Mapper and Reducer must be key-value pairs separated by a tab
Example
yarn jar \
/usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \
-input input -output output \
-mapper mapper.pl -reducer reducer.pl \
-file mapper.pl -file reducer.pl