Spark
A fast and general engine for large-scale data processing
Speed

Easy

Generality
Language Selection
- Scala
- Java
- Python
- R
Updated to Spark 2.4
Now the main entry point is spark instead of sc and sqlContext
Spark Python
PySpark
PySpark Basics
- Can be used together with Anaconda Python distribution
- Over 720 packages for data preparation, data analysis, data visualization, machine learning and interactive data science
Running pyspark interactively
- Running from the command line:
pyspark - Running from the command line using ipython:
module load anaconda2 PYSPARK_DRIVER_PYTHON=ipython pyspark - Running inside a Jupyter notebook
Example
from pyspark.sql import Row
Person = Row('name', 'surname')
data = []
data.append(Person('Joe', 'MacMillan'))
data.append(Person('Gordon', 'Clark'))
data.append(Person('Cameron', 'Howe'))
df = spark.createDataFrame(data)
df.show()
+-------+---------+
| name| surname|
+-------+---------+
| Joe|MacMillan|
| Gordon| Clark|
|Cameron| Howe|
+-------+---------+
spark-submit
Submit job to queue
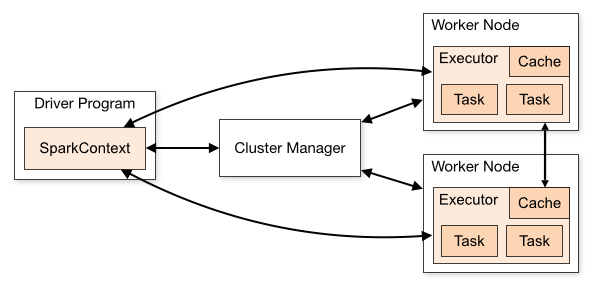
Spark Components
spark-submit Python
# client mode
spark-submit --master yarn \
--name testWC test.py input output
# cluster mode
spark-submit --master yarn --deploy-mode cluster \
--name testWC test.py input output
spark-submit Scala/Java
# client mode
spark-submit --master yarn --name testWC \
--class es.cesga.hadoop.Test test.jar \
input output
# cluster mode
spark-submit --master yarn --deploy-mode cluster \
--name testWC \
--class es.cesga.hadoop.Test test.jar \
input output
spark-submit options
--num-executors NUM Number of executors to launch (Default: 2)
--executor-cores NUM Number of cores per executor. (Default: 1)
--driver-cores NUM Number of cores for driver (cluster mode)
--executor-memory MEM Memory per executor (Default: 1G)
--queue QUEUE_NAME The YARN queue to submit to (Default: "default")
--proxy-user NAME User to impersonate